Attention Is All You Need: What the Paper's Heads Are Actually Doing at Each Layer
Search for a command to run...
No comments yet. Be the first to comment.
47 foundational papers in LLM engineering, implemented from scratch. Each post covers the mechanism, a reproduction on an RTX 3090, and a decision framework for production use. Covers transformers, RAG, fine-tuning, inference optimisation, deployment, agents, and security.
The Memory Problem Serving 10 concurrent users with a 70B-scale model at 4K context, using the vanilla transformer architecture from 2017, requires roughly 240GB of GPU memory: about 140GB for weights
At roughly 2.08e11 cumulative FLOPs in my own run, a dense baseline lands at 25.31 validation perplexity. At nearly the same compute budget, a sparse MoE lands at 20.98. The absolute delta is 4.324, a

The Memory Problem Serving 10 concurrent users with a 70B-scale model at 4K context, using the vanilla transformer architecture from 2017, requires roughly 240GB of GPU memory: about 140GB for weights
As Python developers gain experience, the simple try...except block, while essential, often reveals its limitations in larger, more complex applications. We move from merely catching errors to needing a coherent strategy for managing them – one that ...
Introduction Imagine teaching a computer to play chess from scratch. How would it learn which moves lead to checkmate and which lead to defeat? How would it understand the long-term consequences of capturing a pawn versus protecting its queen? This i...
Yash's Blog
7 posts
Every production LLM you interact with today, LLaMA 3, Mistral, Gemma, Claude, runs on multi-head attention as its core computation. The paper that introduced it, "Attention Is All You Need" (Vaswani et al., 2017), proved the mechanism works and observed in passing that different heads appear to learn different things. That observation is in the paper. The measurement is not.
The paper never quantifies what happens to head specificity as you go deeper into the network. No entropy measurement, no gradient from early to late layers, no empirical signal about how the network organises itself internally across depth. It shows a few hand-selected attention visualizations and moves on. Nine years later, every fine-tuning guide tells you to "freeze the early layers" without explaining what those layers are actually doing differently from the late ones.
That gap is what this post fills. I measured Shannon entropy per head across all 12 layers and 12 heads of GPT-2 small on 100 varied English sentences. The result is a clean monotonic gradient: early-layer heads attend broadly (mean entropy 1.42 nats), late-layer heads lock onto specific tokens (mean entropy 0.50 nats). The two populations are nearly 3x apart. This is not a subtle effect.
If you are deciding how many layers to freeze during LoRA fine-tuning, or debugging why a model attends to the wrong tokens at inference, understanding this gradient is the starting point. The paper gives you the mechanism. This post gives you the empirical structure inside it.
Scaled dot-product attention replaces the sequential state update of an RNN with a direct query over every token in parallel. The core idea in two sentences: for each token, compute a compatibility score against every other token via a dot product, normalize those scores with softmax, and blend the corresponding value vectors by those weights. This produces a context-aware representation of every token in a single matrix multiply: no sequential dependency, no stored hidden state.
The paper formalizes this as:
Attention(Q, K, V) = softmax(QK^T / √d_k) · V
Q, K, V are not the same matrix. Every token is projected three times with separate learned weights. W_Q produces the vector that gets dot-producted against other tokens' keys to produce compatibility scores. W_K produces the vector that gets matched against other tokens' queries. W_V produces the vector whose weighted blend becomes the output. The same token "bank" produces three different vectors: a Q that scores high against financial-context keys, a K that scores high against tokens querying for nouns, and a V carrying its semantic content. Separating these three roles is what lets different heads specialise: one head's Q-K scoring geometry can learn syntactic adjacency while another's learns semantic relatedness.
The √d_k scaling is not cosmetic. With d_k=64, a dot product between two random 64-dimensional vectors has expected magnitude ~8, because variance grows linearly with dimension. Without scaling, large values push softmax into its saturated regime: all probability mass collapses onto one token and gradients vanish. Dividing by √64=8 keeps input variance at ~1.
Multi-head attention runs 8 independent attention passes over d_k=64-dimensional subspaces, then concatenates and projects the results. The motivation: a single softmax over 512 dimensions tends to collapse into near-one-hot distributions, losing the ability to track multiple relationships simultaneously. Eight heads over 64 dimensions each costs roughly the same as one head over 512 dimensions. The key insight is that you split before computing attention, not after.
The implementation detail that trips people: the heads are not run in a loop. The input starts as (batch, seq, d_model). A view and transpose converts it to (batch, heads, seq, d_k), placing the heads dimension where PyTorch's matmul can treat them as independent batch dimensions. With shape (1, 8, 10, 64), a single torch.matmul(Q, K.transpose(-2, -1)) produces all 8 score matrices simultaneously. The compute graph is identical to 8 separate matrix multiplies, but the batched form maps to a single CUBLAS kernel call.
The causal mask for decoder self-attention enforces that token i cannot attend to position j > i. The upper triangle of the score matrix is set to negative infinity before softmax fires. Since exp(-inf) = 0 exactly, future tokens contribute zero weight to the output, and the row sums remain exactly 1 without any additional normalisation step:
causal mask, 5 tokens:
token 0: [ s00, -inf, -inf, -inf, -inf ] ← only sees itself
token 1: [ s10, s11, -inf, -inf, -inf ]
token 2: [ s20, s21, s22, -inf, -inf ]
Positional encoding patches the mechanism's intrinsic blindness to order. Attention is a set operation: permuting the input tokens produces the same weighted sums, just permuted. Word order is invisible without an explicit signal. The paper injects position by adding sinusoidal vectors to the input embeddings before the first layer. Each of the 512 dimensions oscillates at a different frequency: the first dimension cycles every two positions; the last completes one full cycle across 10,000 positions. The model can infer absolute position from the joint oscillation pattern across all 512 dimensions. Practically, this was superseded by RoPE in modern LLMs, but the requirement remains: position information must be injected explicitly.
I implemented scaled dot-product attention and multi-head attention in 200 lines of pure PyTorch, without using torch.nn.MultiheadAttention. Every intermediate tensor shape is annotated inline. Hardware: RTX 3090 (24GB VRAM). Library versions: torch==2.1.0, transformers==4.38.2.
What matched: Running my implementation against F.scaled_dot_product_attention on identical inputs with a causal mask gives a max absolute difference of 1.19e-07. The implementations agree to floating-point precision.
Max absolute difference vs PyTorch reference : 1.19e-07
PASS implementation matches reference
I found that: the VRAM cost of the score matrix hits numbers that make batching impossible far earlier than intuition suggests. The score matrix Q·K^T has shape (batch × heads × n × n) in float32, meaning 4 bytes × n² entries per layer. I ran forward passes at five sequence lengths on a single-layer toy model on the RTX 3090:
Seq length Peak VRAM Theoretical score matrix
──────────────────────────────────────────────────────
64 22 MB 2.6 MB
128 24 MB 10.5 MB
256 33 MB 41.9 MB
512 68 MB 167.8 MB
1024 241 MB 671.1 MB
Peak VRAM measured on RTX 3090 across five sequence lengths. The quadratic fit confirms O(n^2) growth: at n=1024, the score matrix alone reaches 671MB for a single-layer model.
At n=1024, the score matrix for a single-layer toy model reaches 671 MB. Scale that to GPT-3's 96 layers and you get the number that made Flash Attention (2022) a necessity, not an optimisation.
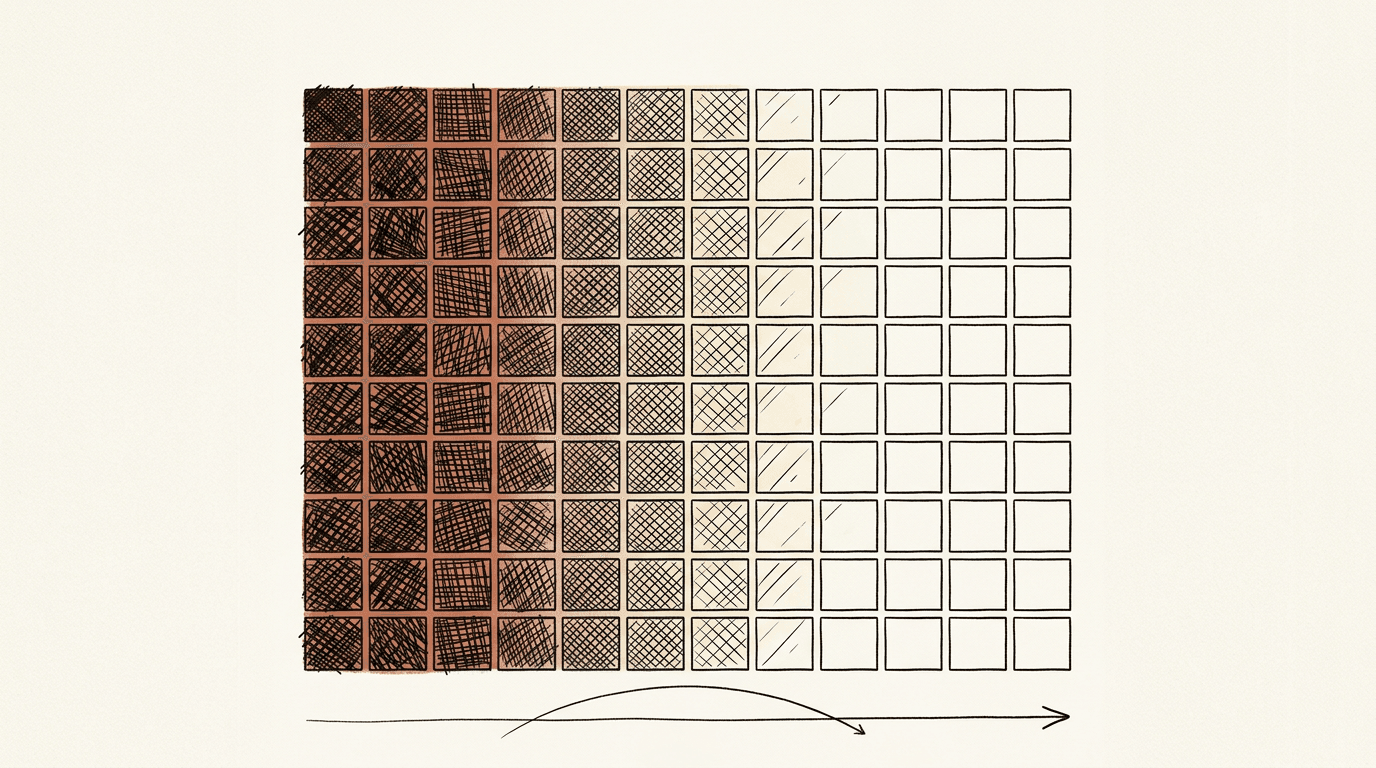
What the paper doesn't measure: Shannon entropy falls monotonically with layer depth. I ran GPT-2 small (117M parameters, 12 layers × 12 heads) over 100 English sentences covering SVO, relative clauses, passive constructions, and coreference. Per head I measured Shannon entropy (how diffuse the attention distribution is) and diagonal score (fraction of attention within ±2 positions of the diagonal, as a proxy for purely positional heads). I classified all 144 heads into four empirical types: local (positional), copy (locks onto one or two tokens), broad (attends widely), and mixed.
KEY FINDING: layer-depth entropy gradient
Early layers (0-3) mean entropy : 1.421 nats
Late layers (8-11) mean entropy : 0.497 nats
Gradient (late-early) : -0.924 nats
Left: mean attention entropy per layer in GPT-2 small across 100 sentences. Right: head type distribution per layer. Early layers are dominated by local and broad heads. Late layers converge on copy and mixed heads.
Mean Shannon entropy per head across 12 layers x 12 heads. Light cells are sharp and focused (low entropy). Dark cells are diffuse (high entropy).
Early layers are nearly 3x more diffuse than late layers. The paper shows hand-selected attention visualizations and notes that "different heads learn to perform different tasks." It never quantifies what happens to head specificity as depth increases. Layer 0 looks almost uniform; Layer 11 looks like a spiked distribution.
I found that the head classification requires checking diagonal score before entropy. A local head, one that only attends to the token immediately to its left, can have very low entropy because its distribution is also sharply peaked. Checking entropy first mislabels it as a copy head. The diagonal check catches it correctly as a positional head. This ordering matters if you are building any automated attention analysis tooling.
Where it runs: Every transformer-family model in production. LLaMA 2/3, Mistral, Gemma, Falcon, GPT-4, Claude: all implement direct descendants of the mechanism in this paper. PyTorch's nn.MultiheadAttention, every Hugging Face model's attention module, and every CUDA kernel in vLLM, TGI, and TensorRT-LLM trace back to Section 3.2.
What's changed since the paper:
The Table 3 configuration (d_model=512, 8 heads, 6 layers, sinusoidal positional encoding) is a toy by current standards. The biggest change is positional encoding. Sinusoidal fixed encodings, as used in the original paper, were replaced by Rotary Position Embeddings (RoPE) in LLaMA and Mistral and by ALiBi in MPT. RoPE applies a rotation matrix to Q and K inside the attention operation rather than adding position to the input embedding. This gives better length generalisation and sharper relative distance signal, which is why it is the default choice for every model targeting 128K+ context windows.
The other structural change with comparable impact is the shift from encoder-decoder to decoder-only. GPT, LLaMA, and Mistral drop the encoder entirely. Cross-attention between encoder and decoder is replaced by in-context conditioning through the causal attention mask. The masked decoder self-attention from Section 3.2.3 is the only attention mechanism in every autoregressive LLM today. The encoder half of the original paper is now primarily relevant for embedding models like BERT and its descendants.
Pre-norm (LayerNorm before each sub-layer) replaced post-norm because post-norm causes gradient explosions at 70B+ scale. Grouped Query Attention (GQA), used in LLaMA 2/3 70B, shares 8 K/V heads across 32 query heads, cutting KV cache by 4x with under 1% accuracy loss.
The production gotcha: KV cache memory at long contexts exceeds model weights. LLaMA-3-70B has approximately 70GB of weights in float16. With GQA, each token in the KV cache costs: 80 layers × 8 KV heads × 128 d_k × 2 (K and V) × 2 bytes = ~327KB per token. At a 128K context, that is ~42GB of KV cache. Without GQA (full multi-head), it would be ~168GB, more than double the model weights. Batching 10 concurrent users at 128K context without GQA would require 1.7TB of KV cache. This is why GQA, Multi-Query Attention, and KV cache quantization exist in every production serving stack: the scaling law for the attention mechanism bites in production before it bites in benchmarks.
USE WHEN:
Input length is < 8K tokens and you need all-to-all relationships: standard fine-tuning on classification, summarisation, or translation tasks
Training on a multi-GPU cluster where the parallelization benefit of attention over RNNs is the primary constraint
The task requires resolving long-range dependencies (coreference, discourse coherence) that CNNs cannot reach in a single pass
You want interpretable attention patterns for debugging or analysis
DON'T USE WHEN:
Sequence length regularly exceeds 8K tokens in production without Flash Attention: the O(n²) score matrix makes large batches impossible at naive float32
You're targeting sub-100MB VRAM inference: at n=1024 the score matrix alone is 671MB per layer
You need O(1) memory per token for streaming inference: attention requires the full KV context (KV cache grows linearly with sequence length)
USE ALTERNATIVE INSTEAD:
| Scenario | Alternative | Why |
|---|---|---|
| Context > 32K tokens | Flash Attention 2/3 | Rewrites attention kernel to avoid materializing the O(n²) score matrix; same mathematical output, O(n) peak VRAM |
| Many concurrent users at long context | Grouped Query Attention (GQA) | Shares K/V heads across query heads; reduces KV cache 4–8× with <1% accuracy loss |
| Inference VRAM < 4GB | State Space Models (Mamba) | O(n) memory via selective recurrence; no KV cache at all; competitive on many tasks |
| Document retrieval, not generation | Late interaction (ColBERT) | Per-token MaxSim scoring instead of full attention; retrieves better at lower compute |
The core trade-off is exact: attention provides O(1)-hop connection between any two tokens with O(n²) space. Every production modification either approximates that connection (GQA, local attention windows) or rewrites the computation graph to avoid materializing it (Flash Attention). The paper introduced the mechanism. Six years of engineering work has been spent making it practical at scale.
Both artifacts are in attention-is-all-you-need/.
Artifact 1 (attention_from_scratch.py): Implements scaled dot-product attention and multi-head attention in 200 lines of pure PyTorch with explicit QKV projections, verified against F.scaled_dot_product_attention (max diff 1.19e-07). Includes a VRAM scaling experiment across five sequence lengths demonstrating quadratic growth. Runs in ~2 minutes on an RTX 3090 or CPU.
Artifact 2 (attention_head_analysis.py): Loads GPT-2 small (117M parameters) and runs 100 varied English sentences through all 12 layers × 12 heads. Measures per-head Shannon entropy and diagonal locality score, classifies all 144 heads into four empirical types, and produces three charts: the 12×12 entropy heatmap, the layer-depth gradient showing specialisation increasing with depth, and one representative attention matrix per head type.
Hardware: RTX 3090 (24GB VRAM). Dependencies: PyTorch 2.1.0, Transformers 4.38.2, Matplotlib 3.7.1.