Exploration vs. Exploitation: A Deep Dive into Multi-armed Bandits
Search for a command to run...
No comments yet. Be the first to comment.
Join my journey through Sutton & Barto’s Reinforcement Learning textbook, distilling complex concepts (MDPs, value functions, Q-learning) into intuitive explanations for BSc CS learners.
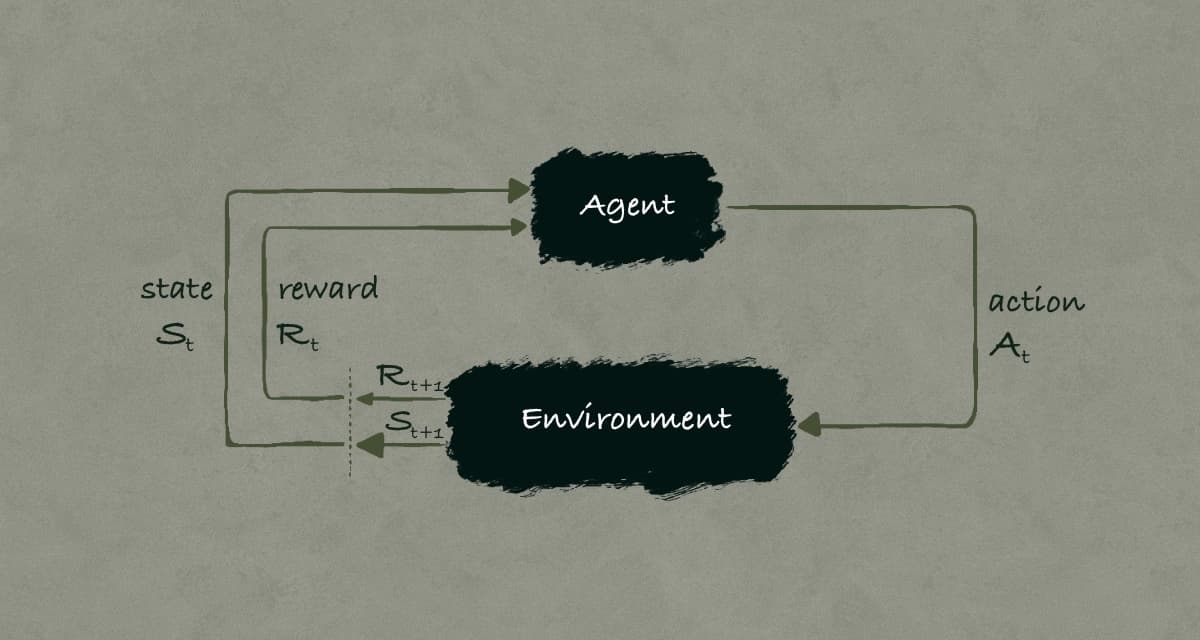
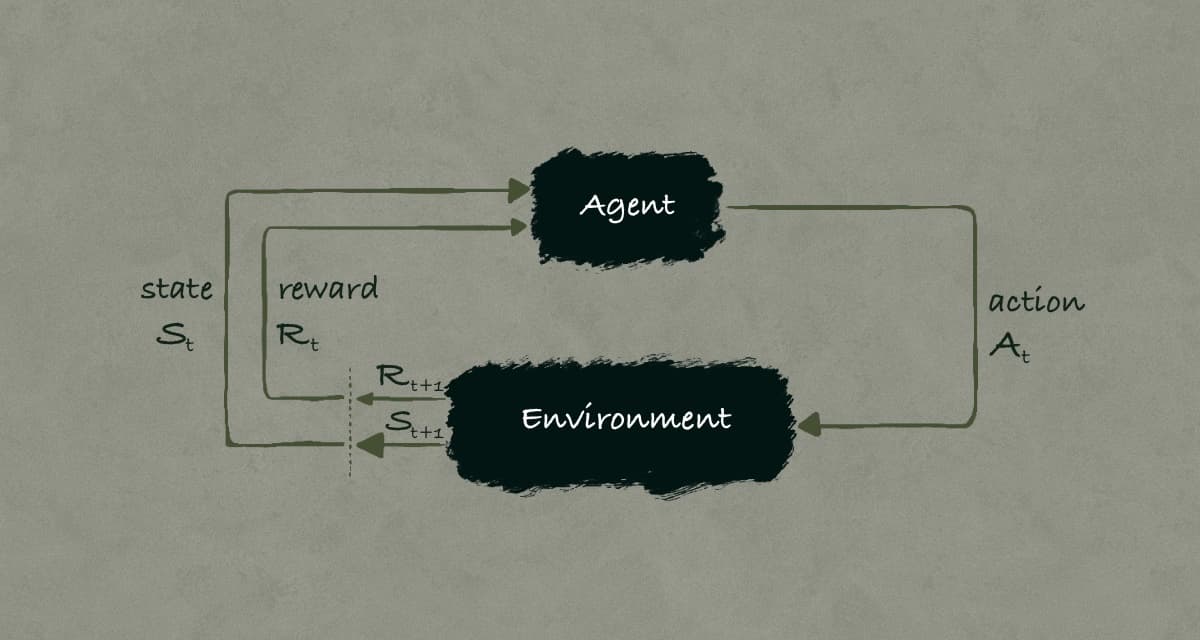
Introduction Imagine teaching a computer to play chess from scratch. How would it learn which moves lead to checkmate and which lead to defeat? How would it understand the long-term consequences of capturing a pawn versus protecting its queen? This i...
At roughly 2.08e11 cumulative FLOPs in my own run, a dense baseline lands at 25.31 validation perplexity. At nearly the same compute budget, a sparse MoE lands at 20.98. The absolute delta is 4.324, a

The Memory Problem Serving 10 concurrent users with a 70B-scale model at 4K context, using the vanilla transformer architecture from 2017, requires roughly 240GB of GPU memory: about 140GB for weights
Every production LLM you interact with today, LLaMA 3, Mistral, Gemma, Claude, runs on multi-head attention as its core computation. The paper that introduced it, "Attention Is All You Need" (Vaswani
As Python developers gain experience, the simple try...except block, while essential, often reveals its limitations in larger, more complex applications. We move from merely catching errors to needing a coherent strategy for managing them – one that ...
Introduction Imagine teaching a computer to play chess from scratch. How would it learn which moves lead to checkmate and which lead to defeat? How would it understand the long-term consequences of capturing a pawn versus protecting its queen? This i...
Yash's Blog
7 posts
Imagine you're at a casino, faced with a row of slot machines (one-armed bandits), each with its own hidden probability of paying out. Your goal is to maximize your winnings over the night, but you don't know which machines have the best odds. This is essentially the k-armed bandit problem - a fundamental challenge in reinforcement learning that elegantly captures the exploration-exploitation dilemma.
In mathematical terms, we have k different actions (pulling different slot machine arms), and each action a has an expected reward, which we call its value q*(a). When we select an action At at time step t, we receive a reward Rt drawn from a probability distribution dependent on the selected action:
$$q^*(a) \doteq \mathbb{E}[R_t | A_t = a]$$
The catch? We don't know these values in advance. We can only estimate them based on our experience, and these estimates are denoted as Qt(a).
This creates our central dilemma: should we exploit our current knowledge by selecting what appears to be the best arm based on our limited experience (the "greedy" action), or should we explore other arms to potentially discover better options? If we always exploit, we might get stuck with a suboptimal arm. If we always explore, we'll learn a lot but might not maximize our rewards.
This isn't just a theoretical problem. A doctor choosing treatments for patients faces this exact dilemma - should they stick with the treatment that has worked best so far (exploit) or try a promising new alternative (explore)? The stakes in such real-world scenarios are often much higher than casino winnings.
To tackle the k-armed bandit problem, we need ways to estimate the value of each action and strategies to select actions based on these estimates.
The most natural approach to estimating action values is to average the rewards we've received when taking that action:
$$Q_t(a) \doteq \frac{\text{sum of rewards when a taken prior to t}}{\text{number of times a taken prior to t}} = \frac{\sum_{i=1}^{t-1} R_i \cdot \mathbb{1}{A_i=a}}{\sum{i=1}^{t-1} \mathbb{1}_{A_i=a}}$$
Where 1predicate equals 1 when the predicate is true and 0 otherwise. This is called the sample-average method, and by the law of large numbers, as we take action a more and more times, Qt(a) will converge to the true value q*(a).
Once we have these estimates, how do we select actions? The simplest approach is the greedy method:
$$A_t \doteq \underset{a}{\operatorname{argmax}} Q_t(a)$$
This always selects the action with the highest estimated value. But as we've discussed, pure exploitation can lead to suboptimal results.
A simple but effective alternative is the ε-greedy method: with probability ε, we select a random action (exploration), and with probability 1-ε, we select the greedy action (exploitation). This ensures that all actions will eventually be tried enough times for their estimates to converge to their true values.
For example, if we have two actions and set ε=0.5, there's a 50% chance we explore randomly (25% chance for each action) and a 50% chance we exploit. So the greedy action has a 50% + 25% = 75% chance of being selected, while the non-greedy action has only a 25% chance.
To evaluate these methods empirically, Sutton and Barto created a testbed with 2,000 randomly generated k-armed bandit problems where k=10. For each problem, the true action values q*(a) were selected from a normal distribution with mean 0 and variance 1. When an action was selected, the actual reward was drawn from a normal distribution with mean q*(a) and variance 1.
Let me walk you through what this means in practice. Imagine one specific bandit problem in this testbed. The true values of the 10 arms might be something like:
[-0.7, 0.5, 1.2, -0.3, 0.8, -1.5, 0.2, 1.5, -0.9, 0.1]
The best arm here is arm 8 with a value of 1.5, but we don't know this in advance. When we pull this arm, we don't get exactly 1.5 as a reward - we get a random value from a normal distribution centered at 1.5. Sometimes we might get 2.3, other times 0.7, occasionally even negative values, though they're less likely.
The results from running different methods on this testbed were revealing:
The greedy method (ε=0) improved quickly at first but often got stuck on suboptimal actions, achieving an average reward of only about 1 out of a possible 1.55.
The ε-greedy methods performed better in the long run because they continued to explore. With ε=0.1, the method explored more and usually found the optimal action earlier but never selected it more than 91% of the time. With ε=0.01, it improved more slowly but eventually performed better.
These results highlight a crucial insight: the value of exploration depends on the specific problem. If rewards were more variable (higher variance), exploration would be even more beneficial. If rewards were deterministic, a greedy approach might work better. And in nonstationary environments, where the best action changes over time, ongoing exploration becomes essential.
When implementing these methods, we need to efficiently compute the action-value estimates. The naive approach would store all rewards and recompute the average each time, but this would require increasing memory and computation as we gather more experience.
Fortunately, we can use an incremental update formula. If Qn is our estimate after n-1 rewards, and we receive a new reward Rn, we can update our estimate as:
$$Q_{n+1} = Q_n + \frac{1}{n} [R_n - Q_n]$$
This elegant formula requires storing only two values per action (the current estimate Qn and the count n) and performs a constant amount of computation per step.
This formula follows a general pattern that appears throughout reinforcement learning:
$$\text{NewEstimate} \leftarrow \text{OldEstimate} + \text{StepSize} [\text{Target} - \text{OldEstimate}]$$
The term [Target - OldEstimate] represents an error in our estimate, and we move our estimate toward the target by a fraction determined by the step size.
Here's a complete algorithm for the ε-greedy bandit method with incremental updates:
textInitialize, for a = 1 to k:
Q(a) ← 0
N(a) ← 0
Loop forever:
A ← {
argmax_a Q(a) with probability 1-ε
a random action with probability ε
}
R ← bandit(A)
N(A) ← N(A) + 1
Q(A) ← Q(A) + 1/N(A) * [R - Q(A)]
This algorithm efficiently implements the ε-greedy approach with sample-average estimation, requiring minimal memory and computation.
In many real-world scenarios, the true values of actions change over time - what was the best action yesterday might not be the best today. Think of our casino example: what if the slot machines were being adjusted throughout the night, changing their payout probabilities?
The sample-average method we've discussed gives equal weight to all rewards, which isn't ideal for tracking changing values. Instead, we can use a constant step-size parameter α:
$$Q_{n+1} \doteq Q_n + \alpha [R_n - Q_n]$$
This results in Qt being a weighted average of past rewards, with more recent rewards given more weight:
$$Q_{n+1} = (1-\alpha)^n Q_1 + \sum_{i=1}^{n} \alpha (1-\alpha)^{n-i} R_i$$
The weight given to reward Ri is α(1-α)^(n-i), which decreases exponentially as the reward gets older. This is called an exponential recency-weighted average.
For example, with α=0.1, the weight of the most recent reward is 0.1, the previous reward gets 0.09, the one before that 0.081, and so on. This allows our estimates to adapt to changing values.
While constant step sizes are great for nonstationary problems, they don't guarantee convergence to the true action values in stationary problems. For convergence, step-size parameters αn(a) must satisfy:
$$\sum_{n=1}^{\infty} \alpha_n(a) = \infty$$
$$\sum_{n=1}^{\infty} \alpha_n^2(a) < \infty$$
The sample-average method with αn(a)=1/n satisfies these conditions, but constant step sizes don't. However, in practice, the ability to track nonstationary problems often outweighs the theoretical guarantee of convergence in stationary ones.
Another approach to encouraging exploration is through optimistic initial values. Instead of initializing our action-value estimates to zero or some neutral value, we set them to be optimistically high - higher than we expect any action's true value to be.
When we select actions based on these optimistic estimates, we'll inevitably be "disappointed" by the actual rewards, which will be lower than our initial estimates. This disappointment drives exploration: as we update our estimates downward for the actions we've tried, untried actions (which still have their optimistic initial values) become relatively more attractive.
For example, in the 10-armed testbed where true action values are normally distributed with mean 0, setting initial estimates to +5 is wildly optimistic. This causes the algorithm to try all actions several times before settling into more exploitative behavior.
The beauty of this approach is that it drives exploration without requiring random action selection. A purely greedy algorithm with optimistic initialization will explore extensively in its early stages.
However, optimistic initialization has a significant limitation: its exploration is inherently temporary. Once all actions have been tried enough to bring their estimates down from the initial optimistic values, the method becomes purely exploitative. If the environment changes later, creating a renewed need for exploration, optimistic initialization can't help.
The Upper-Confidence-Bound (UCB) algorithm takes a more sophisticated approach to the exploration-exploitation trade-off. It selects actions according to:
$$A_t \doteq \underset{a}{\operatorname{argmax}} \left[ Q_t(a) + c \sqrt{\frac{\ln t}{N_t(a)}} \right]$$
Where Nt(a) is the number of times action a has been selected prior to time t, and c > 0 controls the degree of exploration.
This formula balances two factors:
The estimated value Qt(a) (exploitation)
A measure of uncertainty √(ln t / Nt(a)) (exploration)
The uncertainty term increases when an action hasn't been selected for a while (as t increases but Nt(a) doesn't) and decreases when an action is selected (as Nt(a) increases). This naturally drives exploration toward actions with promising values or high uncertainty.
In our casino analogy, UCB is like a strategic gambler who not only considers which machines have paid well so far but also which ones haven't been tried enough to be confident about their payouts.
UCB often performs well in practice, outperforming ε-greedy methods on many problems. However, it's more complex to extend beyond simple bandit problems to the full reinforcement learning setting, particularly for nonstationary problems or large state spaces.
Gradient bandit algorithms take a different approach. Instead of estimating action values directly, they learn a preference Ht(a) for each action. Higher preferences make an action more likely to be selected, but preferences don't have any interpretation in terms of reward.
Actions are selected according to a soft-max (Boltzmann) distribution:
$$\Pr\{A_t = a\} \doteq \frac{e^{H_t(a)}}{\sum_{b=1}^{k} e^{H_t(b)}} \doteq \pi_t(a)$$
Initially, all preferences are equal (e.g., Ht(a)=0 for all a), so all actions have an equal probability of being selected.
After selecting action At and receiving reward Rt, the preferences are updated as:
$$H_{t+1}(A_t) \doteq H_t(A_t) + \alpha (R_t - \bar{R}_t) (1 - \pi_t(A_t))$$
$$H_{t+1}(a) \doteq H_t(a) - \alpha (R_t - \bar{R}_t) \pi_t(a), \quad \text{for all } a \neq A_t$$
Where α > 0 is a step-size parameter, and RˉtRˉt is the average of all rewards up to time t, serving as a baseline.
This update rule increases the preference for the selected action if the reward was higher than the baseline and decreases it if the reward was lower. Non-selected actions move in the opposite direction.
What's fascinating about this algorithm is that it can be derived as a stochastic gradient ascent method, maximizing the expected reward. The derivation involves calculus but shows that the algorithm is moving the action preferences in the direction that increases expected reward.
In our casino example, the gradient bandit algorithm would be like a gambler who develops intuitive preferences for different machines rather than trying to estimate their exact payout rates. After each play, they adjust their preferences based on whether the reward was better or worse than what they've been getting on average.
So far, we've considered nonassociative tasks where there's a single best action (or a best action that changes over time). But in many real-world problems, the best action depends on the situation or context.
Imagine if our casino had multiple slot machines, but their payout probabilities changed based on a visible signal - perhaps a color displayed on the machine. This is an associative search task, also called a contextual bandit problem. We need to learn not just which action is best overall, but which action is best in each context.
For example, if the machine shows red, arm 1 might be best; if it shows green, arm 2 might be best. By learning these associations, we can perform much better than if we treated all situations as the same.
Associative search tasks bridge the gap between the simple k-armed bandit problem and the full reinforcement learning problem. They involve learning a policy (a mapping from situations to actions), but like bandits, each action only affects the immediate reward, not future situations.
Consider a concrete example: suppose you face a 2-armed bandit where the true values randomly switch between two cases:
Case A: action 1 has value 10, action 2 has value 20
Case B: action 1 has value 90, action 2 has value 80
If you can't tell which case you're in, the best you can do is always select action 1, giving an expected reward of (10+90)/2 = 50 per step. But if you're told which case you're facing, you can select action 2 in case A and action 1 in case B, achieving an expected reward of (20+90)/2 = 55 per step.
This example illustrates how contextual information can significantly improve performance, allowing us to adapt our actions to the specific situation we're in.
The multi-armed bandit problem provides a rich framework for understanding the exploration-exploitation dilemma that lies at the heart of reinforcement learning. We've explored several approaches to balancing these competing needs:
ε-greedy methods, which explicitly separate exploration and exploitation
Optimistic initialization, which drives exploration through initially high value estimates
Upper-Confidence-Bound algorithms, which balance exploitation with uncertainty-based exploration
Gradient bandit algorithms, which learn action preferences rather than value estimates
Contextual bandits, which extend these ideas to situation-dependent action selection
Each method has its strengths and weaknesses, and their relative performance depends on the specific problem characteristics. UCB methods often perform best on stationary problems, while constant-α methods adapt better to nonstationary environments.
The exploration-exploitation dilemma extends far beyond bandit problems. It appears in various forms throughout reinforcement learning and is a fundamental challenge in any learning system that must make decisions based on limited information.
As we move from bandits to the full reinforcement learning problem, we'll see how these ideas extend to sequential decision-making, where actions affect not just immediate rewards but also future situations and opportunities. The methods we've explored here provide a foundation for understanding these more complex scenarios.
In our casino analogy, we're no longer just playing individual slot machines - we're navigating a complex casino where each decision affects not only our immediate winnings but also which games we'll have access to next. This is the full reinforcement learning problem, and it's the focus of the rest of our journey.