Reinforcement Learning: First Principles
Initial Concepts and Core Ideas
Search for a command to run...
Initial Concepts and Core Ideas
No comments yet. Be the first to comment.
Join my journey through Sutton & Barto’s Reinforcement Learning textbook, distilling complex concepts (MDPs, value functions, Q-learning) into intuitive explanations for BSc CS learners.
A k-armed Bandit Problem Imagine you're at a casino, faced with a row of slot machines (one-armed bandits), each with its own hidden probability of paying out. Your goal is to maximize your winnings over the night, but you don't know which machines h...
At roughly 2.08e11 cumulative FLOPs in my own run, a dense baseline lands at 25.31 validation perplexity. At nearly the same compute budget, a sparse MoE lands at 20.98. The absolute delta is 4.324, a

The Memory Problem Serving 10 concurrent users with a 70B-scale model at 4K context, using the vanilla transformer architecture from 2017, requires roughly 240GB of GPU memory: about 140GB for weights
Every production LLM you interact with today, LLaMA 3, Mistral, Gemma, Claude, runs on multi-head attention as its core computation. The paper that introduced it, "Attention Is All You Need" (Vaswani
As Python developers gain experience, the simple try...except block, while essential, often reveals its limitations in larger, more complex applications. We move from merely catching errors to needing a coherent strategy for managing them – one that ...
Introduction Imagine teaching a computer to play chess from scratch. How would it learn which moves lead to checkmate and which lead to defeat? How would it understand the long-term consequences of capturing a pawn versus protecting its queen? This i...
Yash's Blog
7 posts
Hey there! Welcome to my blog series on reinforcement learning (RL). I'm currently reading Reinforcement Learning: An Introduction by Sutton and Barto, and as I go through the book, I am making my own notes. I wanted to take this opportunity to document my learning process in the form of blog posts. My goal with this series is to explain RL concepts from my perspective and break them down in an easy-to-understand way. If you have a background equivalent to a BSc in Computer Science, you should be able to follow along comfortably.
That said, I want to be upfront about the fact that I am still learning. I'm no expert in this field, so if I make any mistakes along the way, I sincerely apologize in advance. If you spot any errors or have any suggestions, I would love to hear from you! Feel free to reach out to me via email—I would be more than happy to learn and improve.
As I am self-learning RL, I have also used AI tools to help explain topics that I initially found difficult to grasp. I believe in leveraging available resources to make learning more efficient. I will aim to publish one blog post per chapter of the book. However, due to my full-time job and my ongoing final-year university project, I can't promise a fixed schedule for when each post will be published. But rest assured, I am committed to completing this series, and I hope it will be a useful resource for anyone else looking to learn RL!
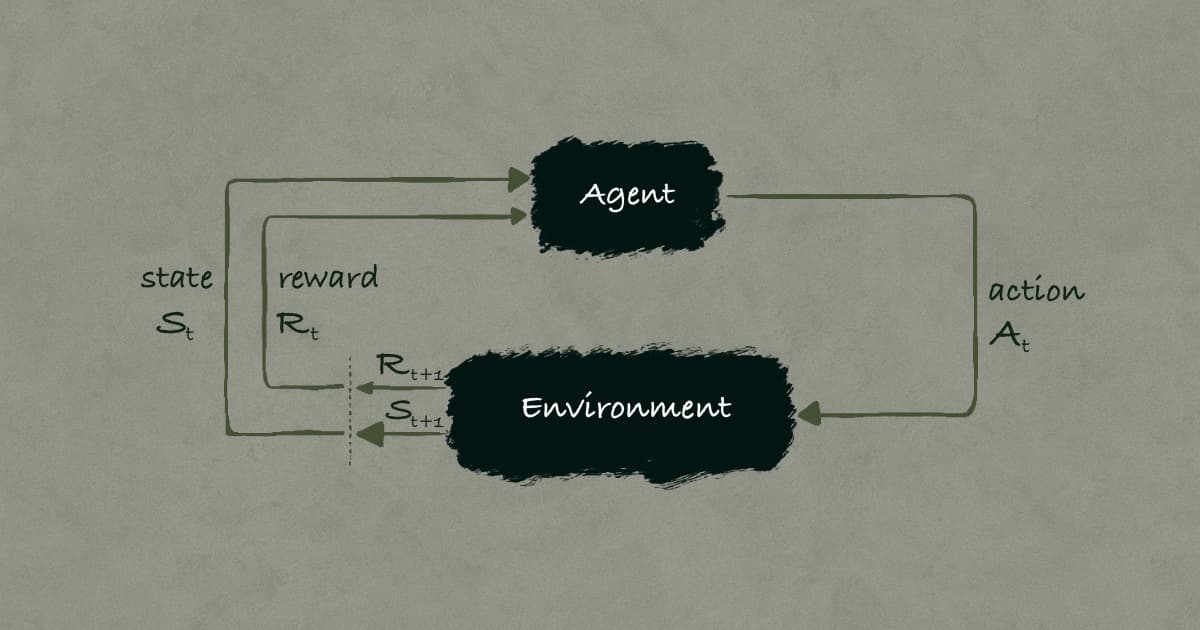
Reinforcement learning (RL) is a paradigm of learning where an agent interacts with its environment to discover optimal actions through a process of trial and error. Unlike supervised learning, where explicit instructions or labeled data guide the learning process, RL requires the agent to explore different actions, assess their consequences, and refine its strategy based on received rewards. One of the most defining aspects of RL is that rewards can be immediate or delayed, making long-term planning an essential component of effective learning.
Trial and Error Learning: The agent learns by continuously experimenting with different actions and observing their consequences.
Delayed Rewards: Unlike immediate feedback systems, RL often involves scenarios where an agent's actions influence future rewards, requiring it to balance short-term gains with long-term benefits.
Reinforcement learning can be categorized in three primary ways:
As a problem to be solved: RL aims to determine the best decision-making strategy to maximize long-term rewards.
As a collection of solution methods: Various computational approaches and algorithms exist to tackle RL problems, including value-based, policy-based, and model-free learning techniques.
As a research field: RL is an active domain of research that seeks to refine algorithms, explore theoretical underpinnings, and expand its applications across multiple industries.
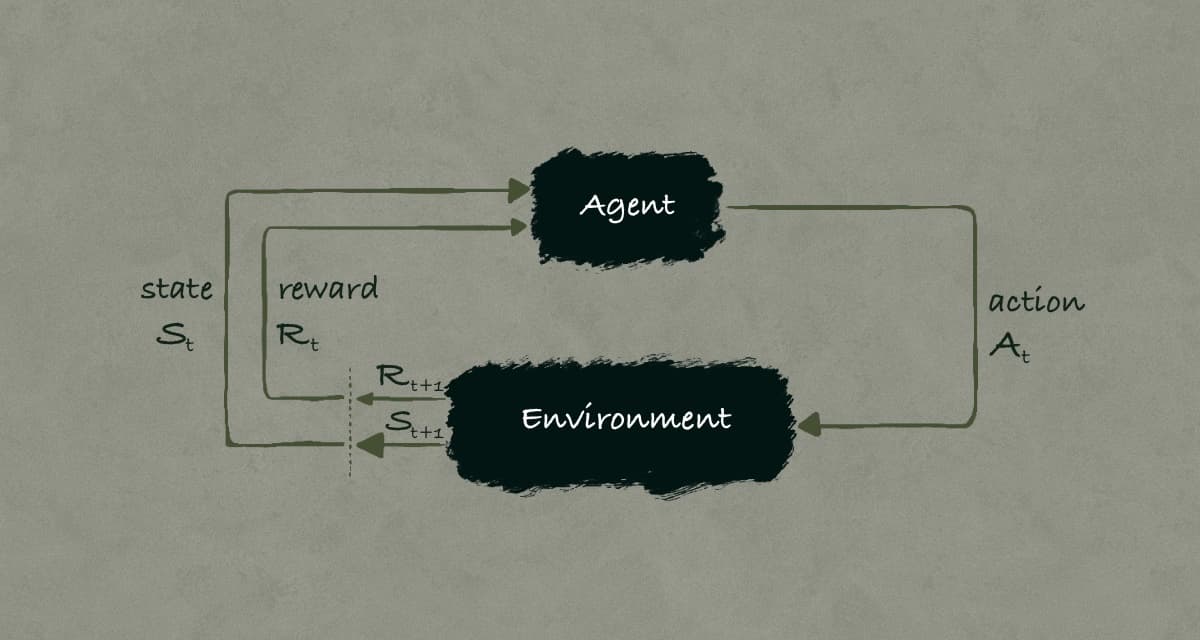
The RL framework is formalized using concepts from dynamical systems theory, particularly as the optimal control of partially known Markov Decision Processes (MDPs). MDPs serve as the mathematical foundation of RL, structuring the learning problem into key components:
Sensation (State Perception): The agent must perceive its environment and identify the current state.
Action (Decision Making): The agent must decide on an action that influences the state of the environment.
Goal (Optimization Objective): The agent’s objective is to maximize cumulative rewards over time by making intelligent action choices.
To function effectively in an RL framework, an agent must possess the ability to:
Sense and interpret the state of the environment.
Take actions that actively influence the environment’s state.
Align its decision-making strategy with a predefined goal that ensures long-term success.
Any approach that successfully enables an agent to navigate these challenges qualifies as a reinforcement learning method.
| Feature | Supervised Learning | Unsupervised Learning | Reinforcement Learning |
| Data Dependency | Requires labeled data for training. | Uses unlabeled data to identify patterns. | No predefined dataset; learns through interactions. |
| Objective | Learns to map input to output using labeled examples. | Identifies hidden structures and relationships in data. | Learns to maximize cumulative rewards through actions. |
| Feedback Type | Direct supervision through labeled examples. | No direct feedback, only pattern recognition. | Reward-based feedback guiding decision-making. |
| Learning Process | Trains using historical data and supervised loss functions. | Clusters or reduces dimensionality of data for better insights. | Explores and exploits different actions to optimize performance. |
| Application | Image classification, speech recognition, spam detection. | Customer segmentation, anomaly detection, recommendation systems. | Game playing, robotics, autonomous systems, financial trading. |
| Decision Dependency | Decisions are independent of past predictions. | Decisions are based on statistical structures. | Decisions depend on past actions and state transitions. |
While the above table highlights key differences, RL introduces additional complexities not present in supervised or unsupervised learning. One crucial aspect is exploration vs. exploitation, where an agent must balance between trying new actions (exploration) and leveraging known information (exploitation) to maximize rewards. RL is also distinct in its emphasis on long-term dependencies, as agents often need to strategize for future rewards rather than merely optimizing for immediate outcomes. Additionally, RL environments are dynamic, meaning that the agent's policy and the environment itself may evolve over time based on interactions.
Another unique characteristic of RL is its reliance on trial-and-error learning, where agents make decisions without prior knowledge and gradually refine their approach through experience. This is particularly useful in scenarios where optimal decision-making cannot be explicitly programmed but must be discovered through continuous learning.
Reinforcement learning (RL) takes a comprehensive approach by considering the entire goal-directed agent interacting with an uncertain environment. In contrast, many other learning approaches focus on isolated subproblems without addressing the bigger picture. While these alternative approaches have yielded valuable insights, their emphasis on fragmented issues presents a significant limitation when dealing with dynamic and evolving environments.
It is typically assumed that an RL agent must operate in the face of significant uncertainty. When RL involves planning, it must address the balance between strategic foresight and real-time decision-making, while also tackling how environmental models are developed and refined. Similarly, when RL incorporates supervised learning, it does so with a clear purpose—defining which capabilities are essential for the learning process and which are not. For learning research to advance meaningfully, subproblems must be examined in ways that align with the broader goal of creating complete, interactive, and goal-seeking agents.
As Sutton and Barto state in their book:
It is not clear how far back the pendulum will swing, but reinforcement learning research is certainly part of the swing back toward simpler and fewer general principles of artificial intelligence.
Reinforcement learning consists of four fundamental elements that define how an agent interacts with its environment and learns over time.
A policy is the strategy that an agent follows while making decisions. It maps the agent's perceived state of the environment to the actions it should take. Policies can be deterministic (choosing a specific action for a state) or stochastic (choosing actions based on probability distributions). The policy serves as the brain of the agent, determining its behavior at any given time.
The reward signal is the primary feedback mechanism in RL. Each action taken by the agent results in a reward, which is a numerical value that indicates how beneficial that action was. The objective of an RL agent is to maximize the cumulative reward over time. Rewards drive the learning process, reinforcing actions that lead to better outcomes and discouraging less optimal actions.
The value function estimates the long-term desirability of a given state. Unlike the reward signal, which provides immediate feedback, the value function helps the agent assess how beneficial a state is in the long run. It enables the agent to make more informed decisions by considering future rewards, rather than focusing solely on immediate gains.
Some RL methods use a model of the environment to predict state transitions and rewards before taking actions. These are called model-based methods. Conversely, model-free methods do not rely on such predictions and instead learn purely from trial and error. A model can enhance planning capabilities by simulating future scenarios and refining decision-making processes.
Imagine a chef who is learning to create the perfect dish. The policy represents the chef's approach to cooking—whether they follow a recipe strictly or experiment with different ingredients. The reward signal comes from the feedback they receive, either from tasting their dish or from customer reviews. Over time, the chef learns which combinations of flavors and techniques result in the best dishes—this is akin to developing a value function, where they refine their intuition for what works best. If the chef keeps detailed notes on ingredient substitutions and cooking methods, they are essentially building a model of the environment, helping them anticipate the outcome of their future creations.
Reinforcement Learning (RL) is a distinct learning paradigm that relies on interaction with the environment rather than labeled data.
Key difference from Supervised and Unsupervised Learning: RL focuses on decision-making through trial-and-error and reward signals.
Core Elements of RL:
Policy: The strategy an agent follows to decide actions.
Reward Signal: Feedback mechanism guiding the learning process.
Value Function: Estimates long-term benefits of being in a particular state.
Model of the Environment (optional): Used for planning in model-based methods.
Exploration vs. Exploitation: Balancing between trying new actions and leveraging past knowledge.
Delayed Rewards: Actions may not provide immediate benefits, making long-term planning crucial.
Markov Decision Processes (MDPs): The mathematical framework behind RL.
Trial-and-Error Learning: RL agents learn through continuous interaction rather than pre-labeled data.
Dynamic Environments: RL methods adapt to changing conditions and optimize policies over time.